1
今天小激动又有新妹纸加入,新人任务里竟然有一条是要求生活组长为新妹纸唱一首歌。
说真的,这妹纸,还真是哥的菜,就像名字一样,茶茶,腼腆又可人。既然这样,那哥就唱一首伍佰的《爱你一万年》送给新妹纸吧。
2
晚上公司集体复盘。本次复盘最主要的三个点是:层级设定、公司对每个人的年终评定、有赞币。
说到有赞币,难免要提到晓晓,看这壮观的景象,晓晓一个人都可以操纵有赞货币市场了 ![]()

下面这张照片不知是哪路摄手所摄,恁是把个拥挤的活动室拍得所此高大上:

看看吧,下面这个才是真相:

1
今天小激动又有新妹纸加入,新人任务里竟然有一条是要求生活组长为新妹纸唱一首歌。
说真的,这妹纸,还真是哥的菜,就像名字一样,茶茶,腼腆又可人。既然这样,那哥就唱一首伍佰的《爱你一万年》送给新妹纸吧。
2
晚上公司集体复盘。本次复盘最主要的三个点是:层级设定、公司对每个人的年终评定、有赞币。
说到有赞币,难免要提到晓晓,看这壮观的景象,晓晓一个人都可以操纵有赞货币市场了 ![]()
下面这张照片不知是哪路摄手所摄,恁是把个拥挤的活动室拍得所此高大上:
看看吧,下面这个才是真相:
上午出门忘记带现金了,只带了个手机。按计划一共要去五个地方买东西,然后就问可以用支付宝或者微信支付吗?
这下可以很好的利用碎片时间记日志了。
看到几个骚年在刷朋友圈。
第一期“有赞少年”(管培生)聚会。课题:学会享受。



今天早早起来,一车人去练车,没想到我们不在公司,本周末的技术分享有猛料!
分享主题:kof97深入浅出,从入门到精通。
分享人:小黑
这主题,充分彰显了我厂屌丝在厂里的生活是多么的丰富多彩。
11 点,技术分享准时开始。看着大家在朋友圈发的照片,也只能流流口水了。



原计划在 2014 年结束的,结果由于经常有选手不在,一拖再拖。奖杯都造好了,放在兰兰那里。兰兰有点慌,说,今天一定要结束了,没想到还真的就结束了。最后的冠军竟然是吃洗衣粉的小龙和天赋极高的黑马安冬的组合。
本届赛事由于大部分高手都抽到 A 组,导致 A 组成了死亡之组,像叉老师大姚周俊等绝顶高手都早早爆冷出局,而像我和 Ray 这样的渣渣组合却意外出线。这充分说明一个道理:赌球有风险,入市需谨慎。


对于我这个老移动来说,手机上装个移动营业厅的 APP 还是蛮有用的,只是这个 APP 有一点实在是二,每登录一次就发送一条短信给我,叫我去下载移动营业厅的 APP。妈蛋!我正在用着这个 APP,还老是叫我去下载这个 APP,天底下还能找到第二个这么二的 APP 吗?
前两次复盘的时间有点长,今天复盘为了不是特别影响工作,所以时间卡得紧了些。不过这样一来,反而造成一些负面效应,就是大家都想着早点结束,结果讨论不够深入,氛围没有前两次好。另一个和人多了也有关系,坐的是长桌包厢,发言的时候,离得远一些的人不太听得清。
有小伙伴提出疑虑,复盘上提出的问题,后续也没有人去执行,所以觉得复盘的意义似乎不是太大。
其实很多新人不知道,团队成立以来,从第一次只有几个人的复盘开始,就不是以解决问题为目的去复盘的。大家聚一起,聊一聊过去一个月(现在是两个月)的收获,遇到的问题,对公司的建议等等,主要目的还是一个“聚”。

PS:一直没有整理上次三台山的照片,昨天整理一下洗出来。大师拍的几张特写好赞。

两个月过得好快,又要开始复盘了。小组现在有 20 个人,找个复盘地点实在不容易。allface 有点腻了,想找找别的。
政委推荐去支付宝楼下的巴顿咖啡。中午我和叶子去踩点,发现那里有点吵,地方也有点小,也没有长桌。
然后我们又打车去了益乐路,叶子听夕雪说那里有一个比较家静的地方,结果到了目的地,发现是个酒吧,白天还不开门。
于是我们有点扫兴的从益乐路上走回来,一路看看有没有合适的点。
叶子突然说好想去海角七号吃饭,正好我们午饭也还没吃,就进去看看。没想到里面正好有长桌包厢,能坐 20 个人,好巧好巧,果然是要出来多走走。
于是明天的复盘就定在这里了。
午饭在这里吃,味道还不错。
早上带小孩去打疫苗。像以前一样,先到小区门口叫辆的,和司机说进小区里接小孩,愿意多给 10 元。最后到目的地总共给 22 元。
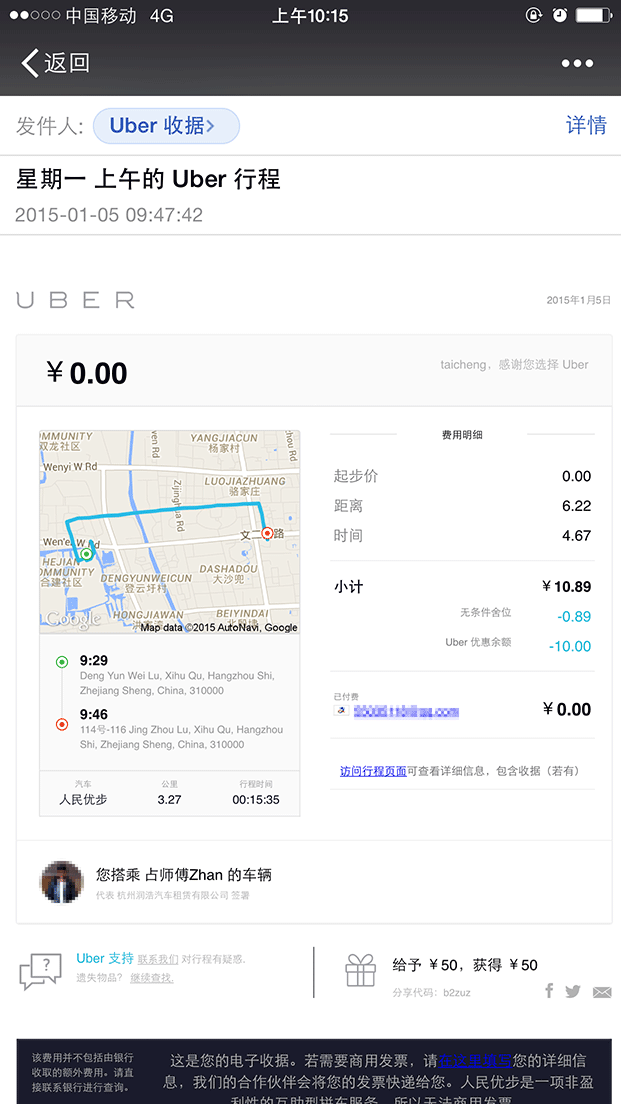
打完疫苗,体验一下 Uber,这么偏的地段,没想到马上就有司机打电话过来接单了,约 8 分钟到,滴滴、快的根本没法比。
我说要去小区里接个小孩,司机态度相当好,也不用多付钱。最后送到家里只花了 10 元。本来是 10.89,零头被“无条件舍位”了。看来注册时填写别人邀请码送的 50 元可以用五次 ![]()
下车也不用付钱,Uber 系统会自动扣,扣完还会发收据到邮箱。
周末升级了 OS X Yosemite 后,快盘网页版不能下载文件了。
今天上午把这个问题反应给快盘网页版客服,下午问题就解决了,很高效,赞一个。
Hi,您反馈的问题有新回复了!
您写道:mac系统升级到 OS X Yosemite 后,快盘网页版不能下载文件了。
回复:您好,推荐您再重新尝试下呢,目前网页上无法下载的问题已经成功处理了。
今天 maggie 家的薛医生来我厂义诊,赞。可惜妹纸屌丝们都比较害羞,咨询量好像不是特别高。我觉得应该开分享,给大家上一课,讲一些医学常识,大家当场发问,那样的形式可能更赞。
今天的技术分享来自川神,爆棚。

分享主题:Nutch
分享人:尚川
课程背景:Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本之后,Nutch已经从搜索引擎演化为网络爬虫,接着Nutch进一步演化为两大分支版本:1.X和2.X,最大的区别在于2.X对底层的数据存储进行了抽象以支持各种底层存储技术。在Nutch的进化过程中,产生了Hadoop、Tika和Gora三个Java开源项目。如今这三个项目都发展迅速,极其火爆,尤其是Hadoop,其已成为大规模数据处理的事实上的标准。Tika使用多种现有的开源内容解析项目来实现从多种格式的文件中提取元数据和结构化文本,Gora支持把大数据持久化到多种存储实现。
课程大纲:
1、Nutch是什么?
Nutch是Apache旗下的Java开源项目,最初是一个搜索引擎,现在是一个网络爬虫。
2、Nutch的设计初衷?
商业搜索引擎不开源,搜索结果不纯粹是根据网页本身的价值进行排序,而是有众多商业利益考虑。Nutch提供了开源的解决方案,帮助人们很容易地建立一个搜索引擎,为用户提供优质的搜索结果,并能从一台机器扩展到成百上千台。
3、为什么要学习Nutch?
搜索技术是信息时代的必备技术之一,没有搜索功能的软件是无法想象的,而搜索引擎是搜索技术的集大成者。通过Nutch的学习,可以对百度、谷歌这样的搜索巨头的内部机制有所了解,并能根据自己的需要打造适合自己的搜索引擎,当然,也可以把搜索技术应用到几乎所有的软件开发中
4、Nutch的设计目标 ?
5、Nutch的发展历程?
6、Nutch的整体架构?
插件机制、数据抓取、数据解析、链接分析、建立索引、分布式搜索等。
对于一个搜索引擎来说,最终可能由成百上千台服务器组成,然而,初创公司最初可能只有几台机器作为尝试,随着公司的发展逐步增加机器,因此,线性可扩展的分布式存储与分布式计算是至关重要的。
Nutch参考了Google的两篇论文:MapReduce计算模型以及GFS存储模型,并做了实现,后来把这两大部分剥离出来形成独立的开源项目Hadoop。由此可知,Hadoop诞生于Nutch,核心由分布式计算和分布式存储组成,是MapReduce和GFS的JAVA开源实现。
Nutch使用HDFS作为存储实现一直持续了很多年,然而使用HDFS有许多限制,后来考虑对存储层进行抽象,剥离并形成了新的开源项目Gora,以支持多种存储技术,包括RDBMS和NoSQL。
对于搜索引擎来说,需要抓取各种各样的文件,解析这些不同格式的文件是一个难题,为了简化设计,也为了重用,于是诞生了Tika,一个专为内容分析而诞生的工具箱。
7、Nutch 3大分支版本?
8、Nutch的应用领域?
站内搜索引擎、全网搜索引擎、垂直搜索引擎、数据采集
9、nutch的使用?
一些具体的实践方法及演示

 浙公网安备 33010602001796号
浙公网安备 33010602001796号